RegExp类型
声明
一个正则表达式就是一个模式和标志的组合体
定义方式:字面量/构造函数
1 | var reg1 = /[ba]ct/g; |
模式:任何简单或复杂的正则表达式,可以包含字符类、限定符、分组、向前查找、反向引用
标志:i(不区分大小写) / g(全局模式应用于所有字符串) / m(多行模式到达文本末尾会继续查找下一行),每个表达式可以有一个或多个标志
构造函数方法参数都是字符串,所以正则表达式需要双重转义
| 字面量模式 | 构造函数字符串 |
|---|---|
/\[ba\]ct/ |
'\\[ba\\]ct' |
/\d{2}/ |
'\\d{2}' |
/\\hello/ |
'\\\\hello' |
构造函数和字面量差异:
首先字面量方法不会调用构造函数
其次在ES3时字面量法共享同一个正则表达式实例,构造函数每次调用都是生成一个新的实例,会导致问题代码如下1
2
3for(var i=1; i<10; i++){
/cat/g.test('cathssjdhfhudhkshd')
}
全局模式下,当第二次查找的时候会从上次匹配项后面开始查找至结尾返回false
但是ES5之后规定字面量法像调用构造函数方法一样,每次创建新的实例
元字符
( ) [ ] { } \ | ? ^ $ * + .,若要展示元字符是需要转义的
-元字符^ 匹配字符串的开始位置(写在单元项前),如果有m标志,也匹配\n或\r之后的位置,即重新开始的一行字符串也算是开始位置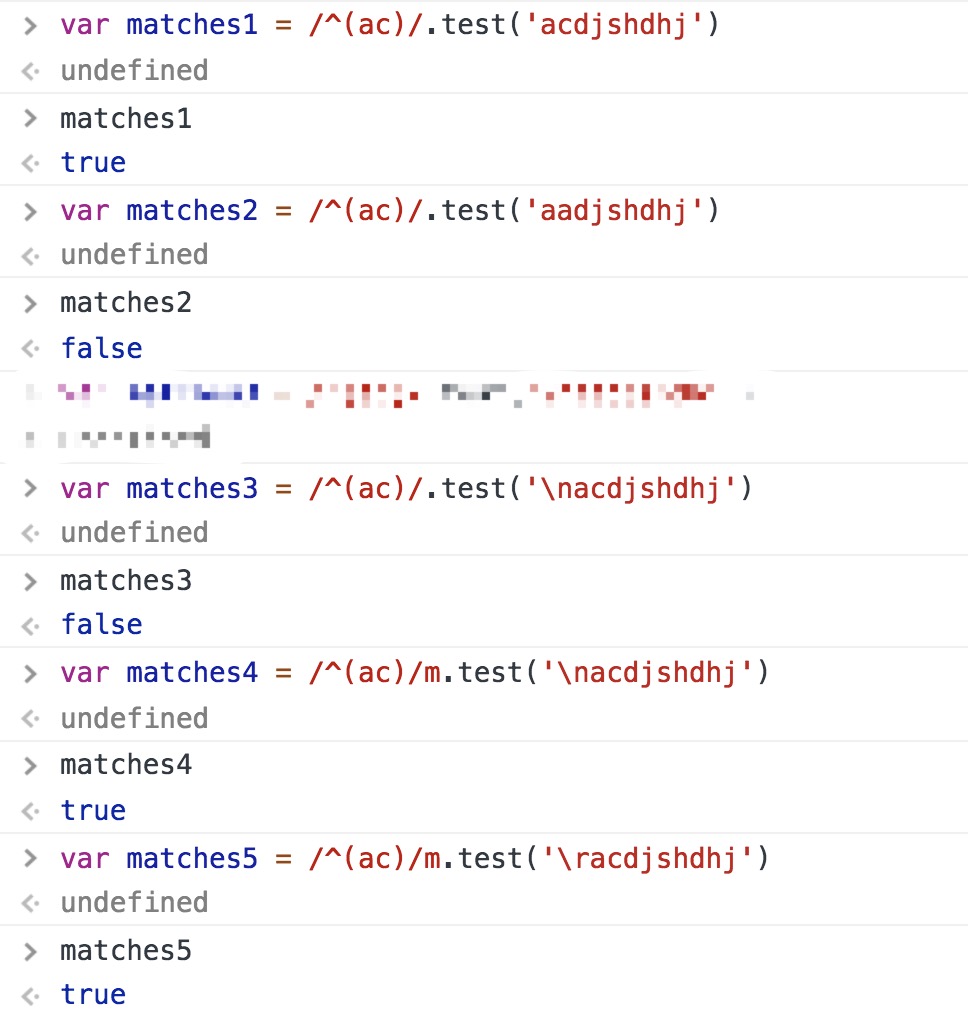
$ 匹配字符串的结束位置(写在单元项后),如果有m标志,也匹配\n或\r之前的位置,即折行后的一行字符串末尾也算是结束位置
. 匹配除换行符(\n或\r)以外的所有字符
\d 匹配数字,相当于[0-9]\D 匹配非数字的字符,相当于[^0-9]\w 匹配字母/数字/下划线,相当于[A-Za-z0-9_]\W 匹配非字母数字下划线的字符,相当于[^A-Za-z0-9_]\s 匹配任意不可见字符,空格/换行/制表等\S 匹配任意可见字符\b 匹配单词和空格间的位置,匹配的是位置而不是那个空格
\B 匹配非单词边界
-限制符* 重复任意次,相当于{0,},例/zo*/能匹配z/zo/zoo…+ 重复1次或多次,相当于{1,},例/zo+/能匹配zo/zoo,但不能匹配z
? 重复0次或1次,相当于{0,1},例/do(es)?/能匹配’do’中的’do’也能匹配’does’/‘doeses’中的’does’
⚠️?还有个功能,当在任意限制符后面时* + ?{},匹配模式为非贪婪模式(默认是贪婪模式尽可能多的匹配),尽可能少的匹配
⚠️?结合()的其他功能:(?:pattern) 非捕获的匹配,可以简化一丢丢|的用法
(?=pattern) 非捕获的匹配,正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串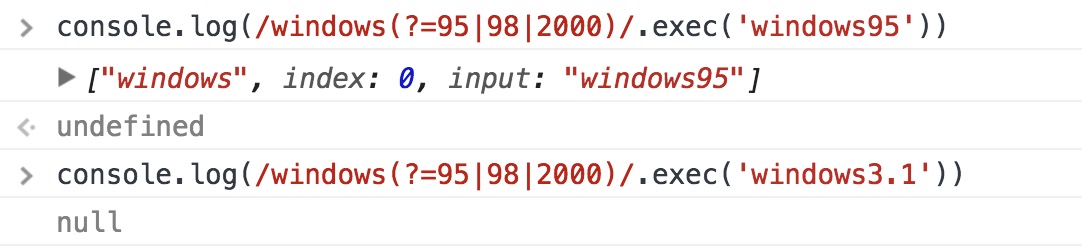
(?!pattern) 非捕获的匹配,正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串
(?<=pattern) 非捕获的匹配,反向肯定预查
(?<!pattern) 非捕获的匹配,反向否定预查
{n} 重复n次{n,} 重复n次或者大于n次{n,m} 重复n到m次
-其他x|y 匹配x或y[xy] 字符合集,匹配任意一个字符,例/[ba]ct/匹配bat或cat,.和*在合集中没有特殊含义

[^xy] 反字符合集,匹配非xy的任意字符[a-z] 字符范围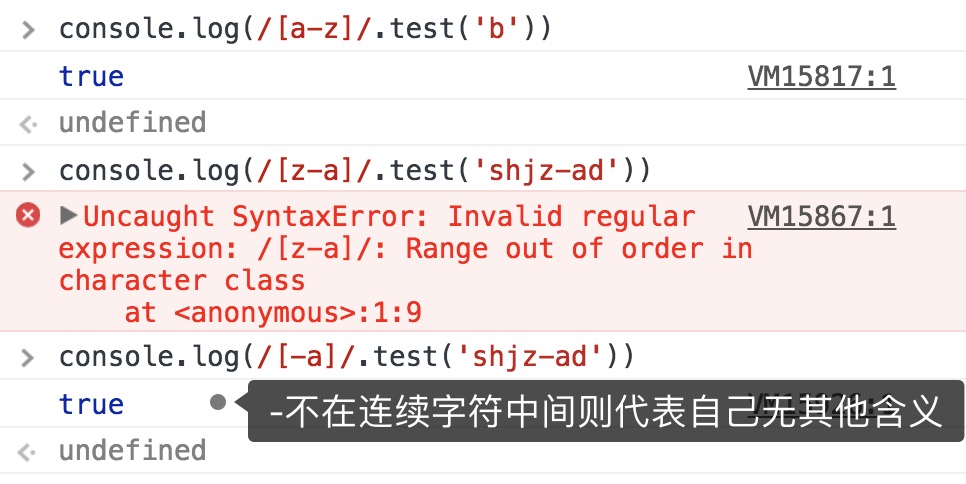
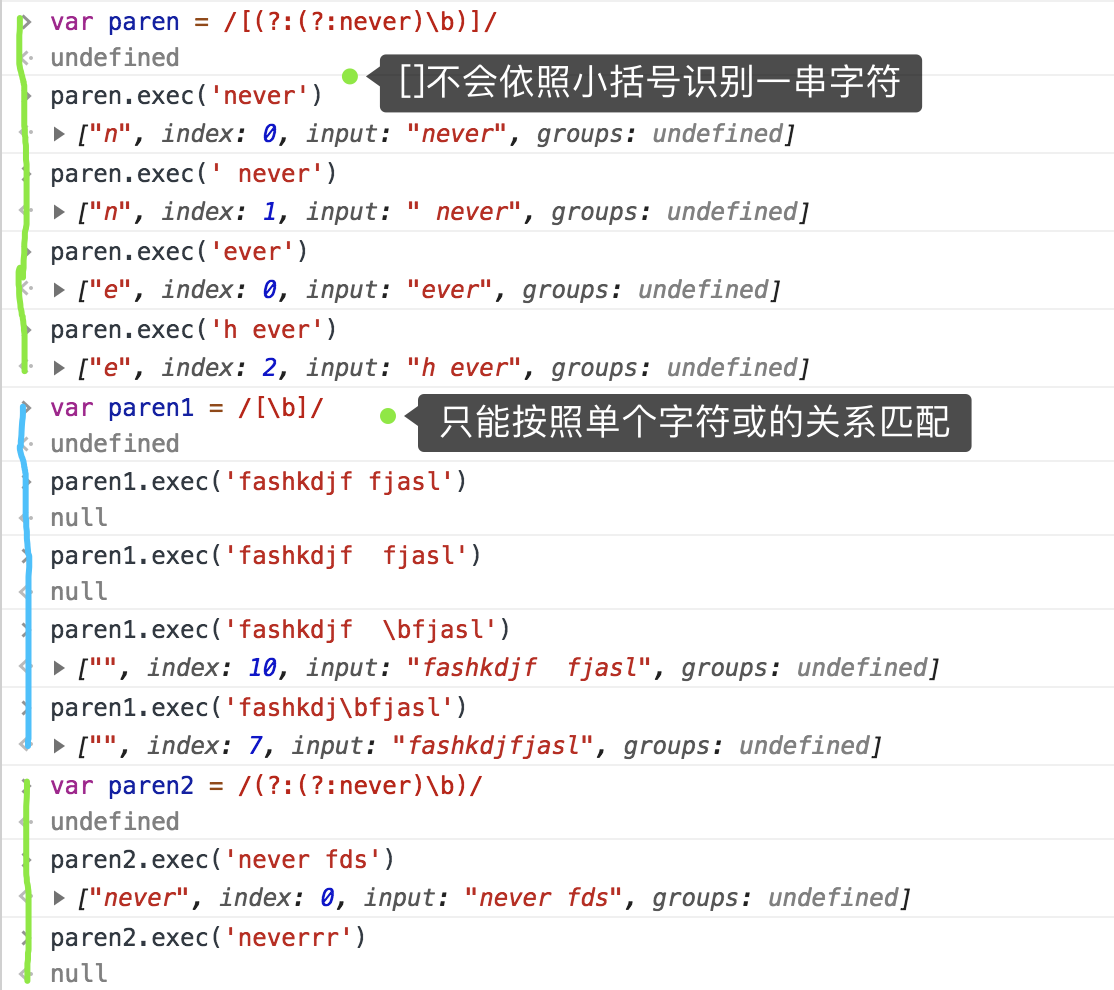
[^a-z] 反字符范围[\b] 匹配一个退格,不要和\b混淆(xy) 捕获分组
实例属性
global 全局标实ignoreCase 忽视大小写标实multiline 多行模式标实lastIndex 开始搜索下一个匹配项的字符位置source 正则表达式的字符串表示,无论声明用什么方式,该属性都是字面量形式的字符串表示
没有什么用,在声明正则时都标注了属性
实例方法
exec
专门为捕获组而设计
1⃣️返回包含匹配项信息的数组,第一项是匹配项,后面项是捕获组匹配项(若没有捕获组则数组只一项),是Array实例但是包含两个额外属性index(匹配项在字符串中的位置)input(应用正则的字符串)
2⃣️若没有匹配项返回null

⚠️g全局模式每次都返回一个匹配项,但是对同一个字符串多次调用exec会继续查找新的匹配项,否则非全局下每次都返回第一个匹配项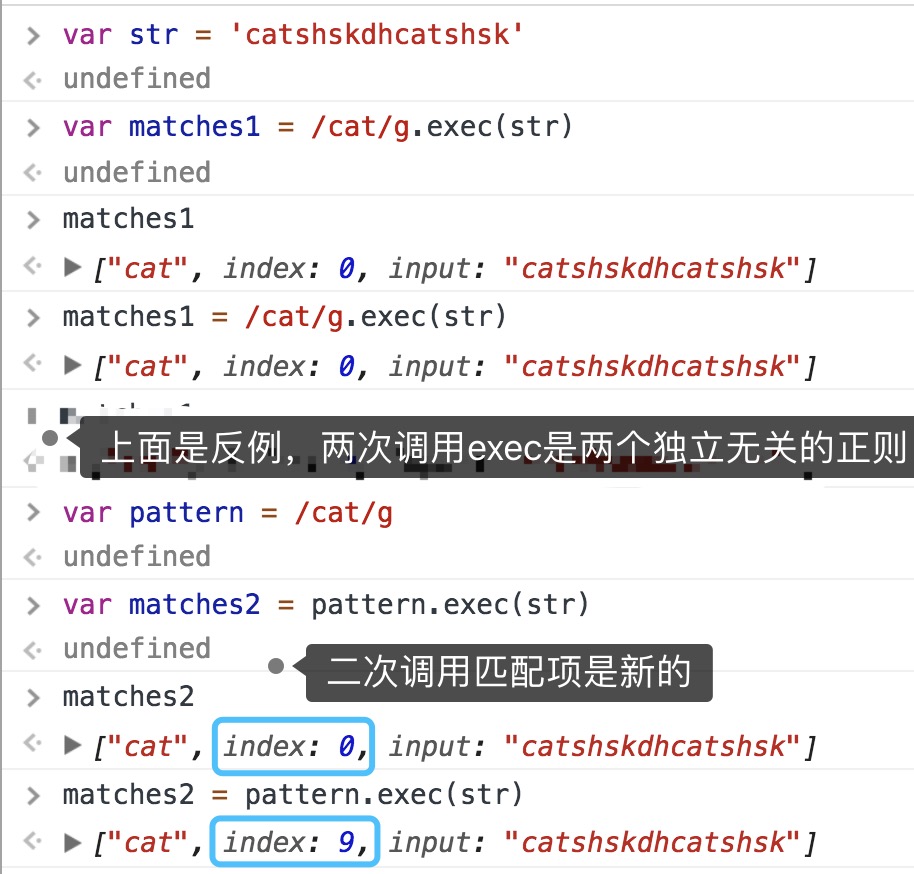
test
只想知道是否匹配,不关心其文本内容
返回值匹配true不匹配false
补充全局模式也适用于test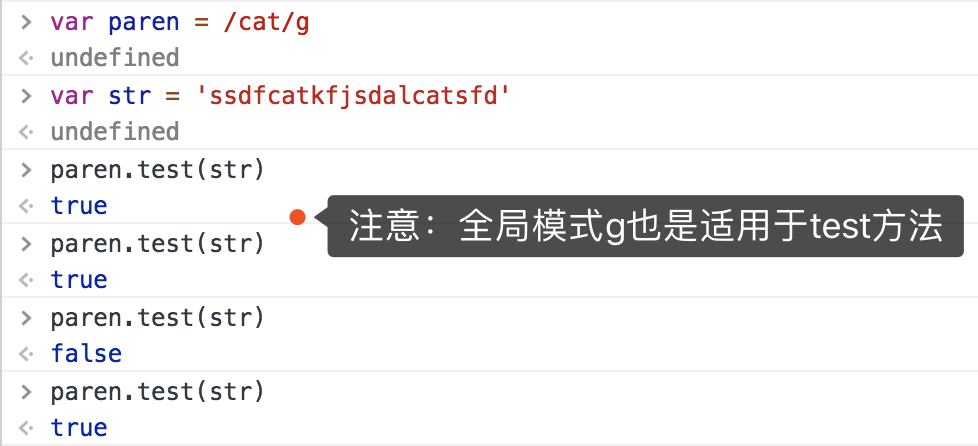
继承方法
toLocalString() toString()返回字面量的字符串表示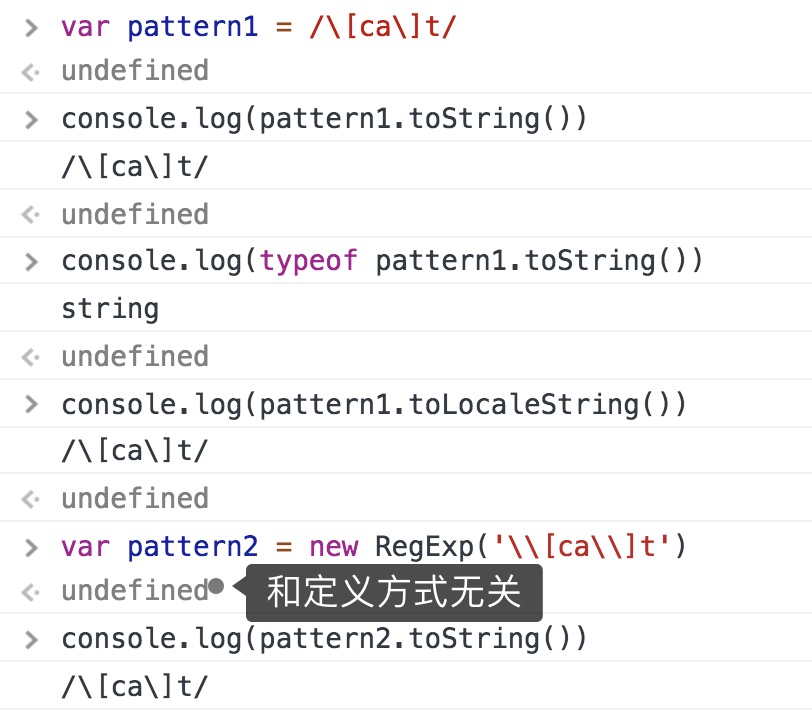
valueOf()返回正则本身
构造函数属性
适用于作用域中所有正则表达式,并跟随最近一次执行正则操作而改变
可以通过两种方式长属性名/短属性名访问,短属性名大都不是有效标识符,so必须用方括号法访问
| 长属性名 | 短属性名 | 说明 |
|---|---|---|
| input | $_ |
最近一次要匹配的字符串 |
| lastMatch | $& |
最近一次匹配项 |
| lastParen | $+ |
最近一次匹配的捕获组 |
| leftContext | $` |
input中位于匹配项前的文本 |
| rightContext | $' |
input中位于匹配项后的文本 |
| multiline | $* |
是否所有表达式都使用多行 |
浏览器的兼容性未测待定…
此外还存在9个用于存储捕获组的属性,访问方式依次是RegExp.$1、RegExp.$2…RegExp.$9,分别存储第一个、第二个…第九个捕获组
虽然调用test()只返回一个true,但是这些属性会自动填充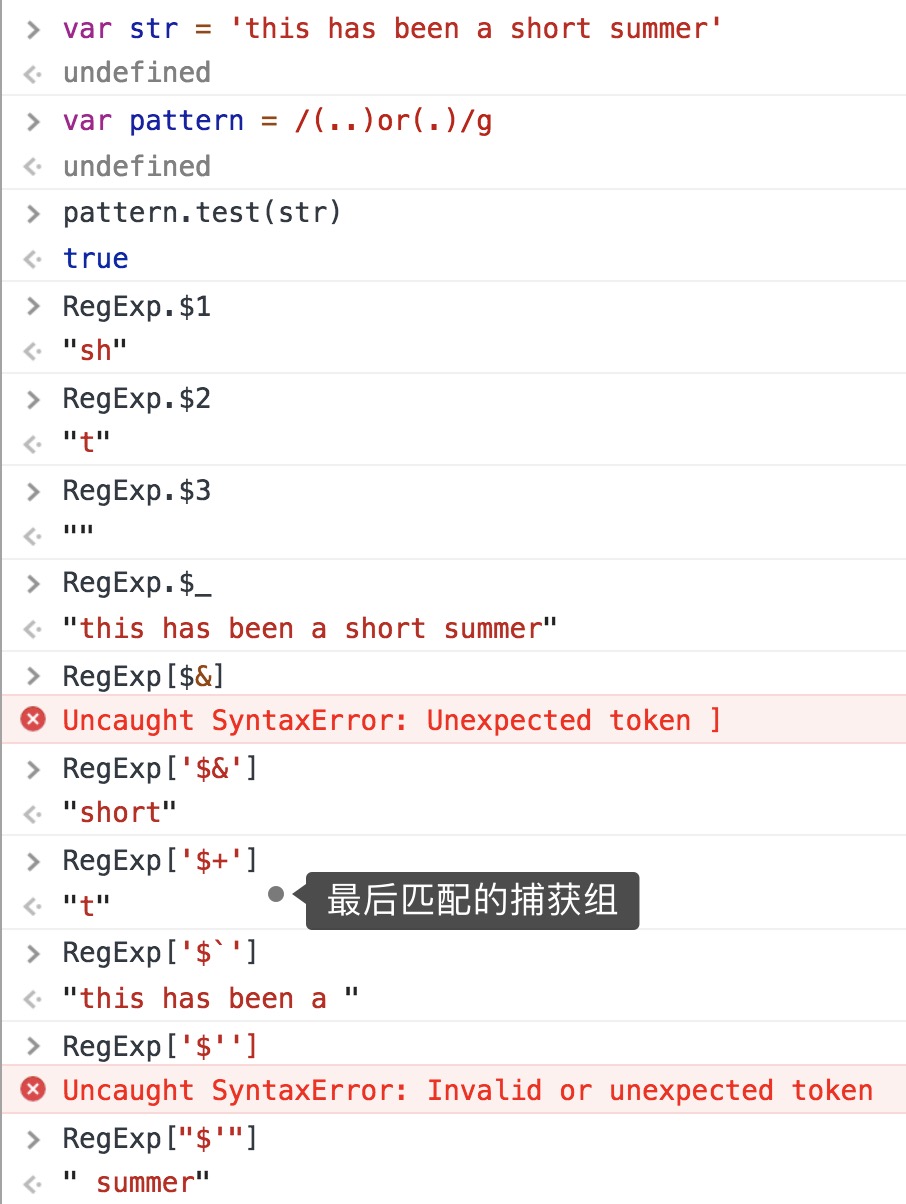
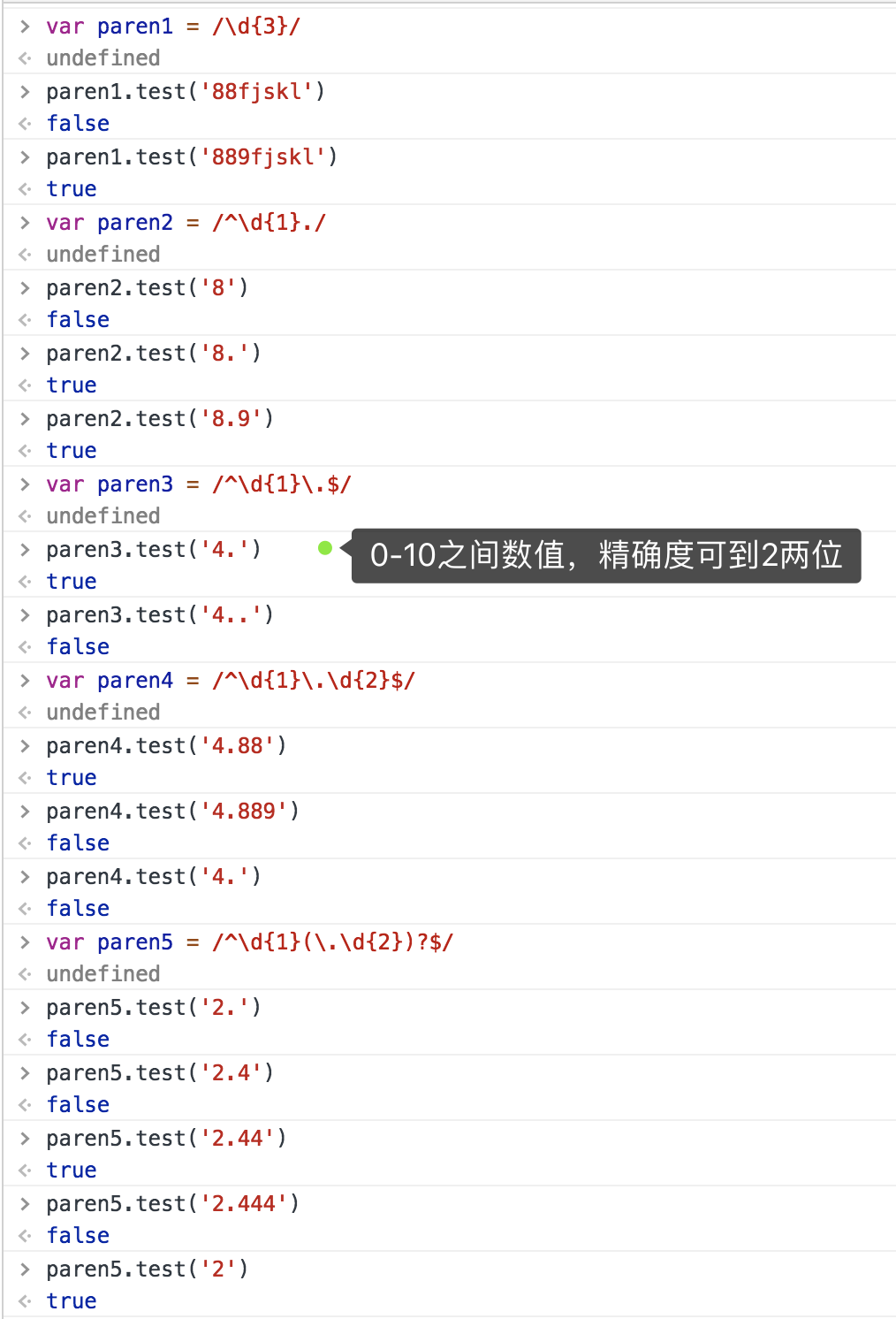
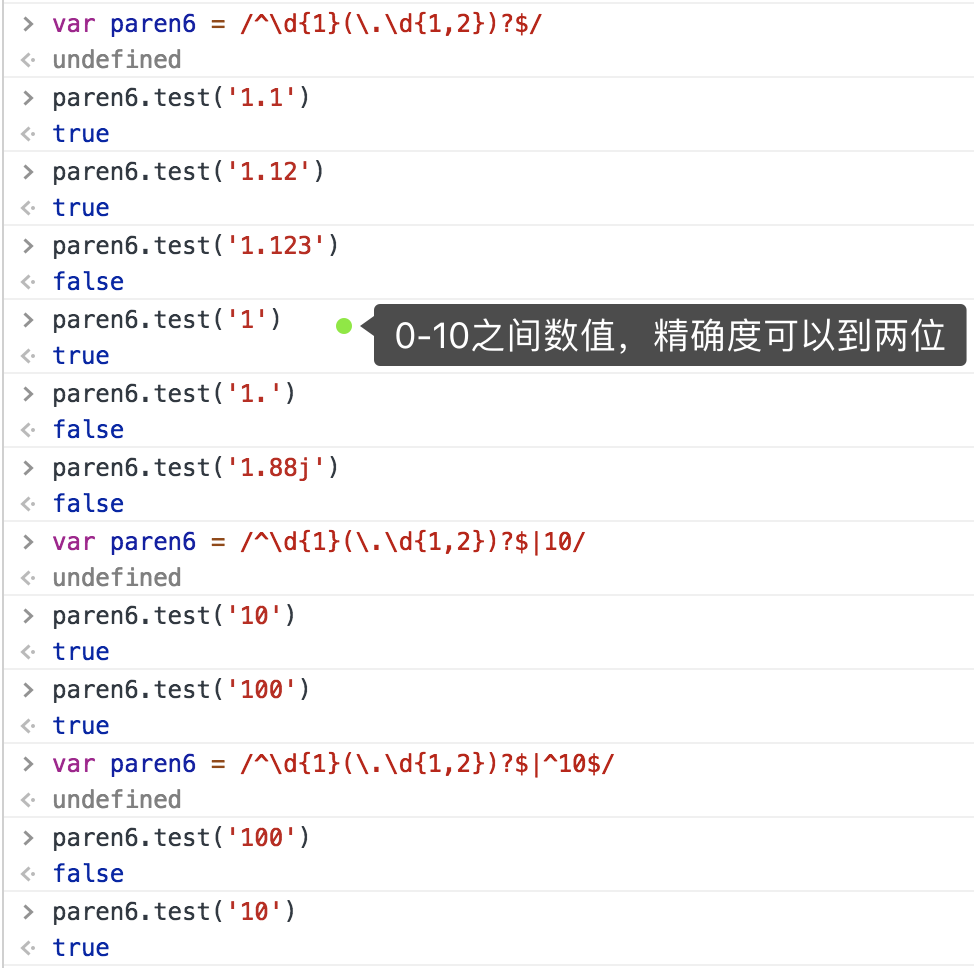
最后写一个0-10之间的数值,精确度可以到两位的例子