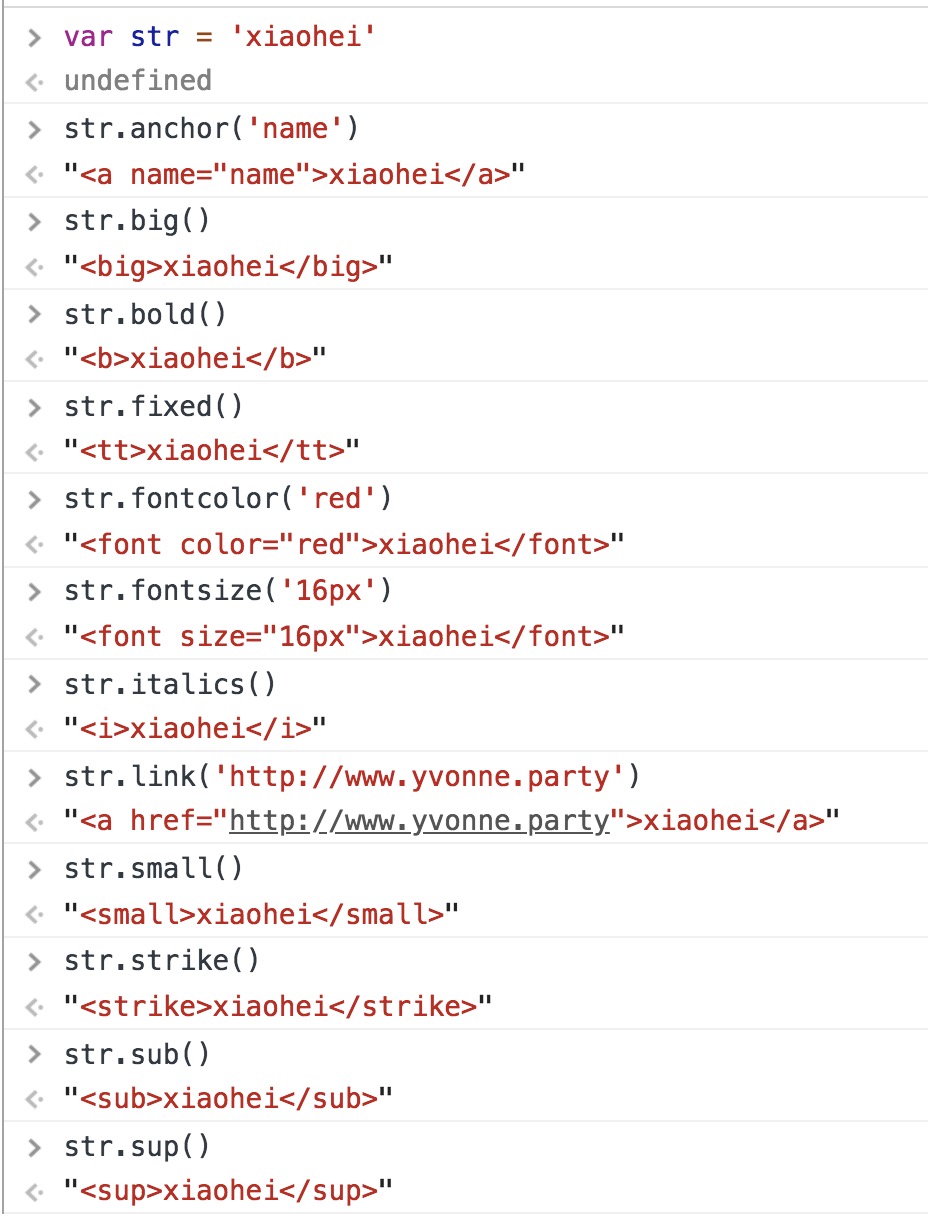
基本包装类型
为便于操作基本类型,ECMAScript提供了特殊的引用类型:Boolean Number String,这些包装类型与引用类型相似,同时具有各自的基本类型的相应地特殊行为
创建方法:
自动创建 => 在读取对应的基本类型时会自动创建一个对应的基本包装类型,实际的过程是:创建基本包装类型实例=>在实例上调用指定的方法=>销毁这个实例,因此在读取模式下能直接调用一些方法来操作这些数据,但是对象只存在于这行代码执行的瞬间
Object构造函数法 => 工厂方法一样,通过传入值的类型返回相应基本包装类型的实例1
2
3var obj = new Object('text')
var obj = new Object(3)
var obj = new Object(false)
Boolean Number String构造函数法 => 绝对必要情况下再做,不然容易分不清处理的是基本类型还是基本包装类型1
2
3var obj = new Boolean(true)
var obj = new Number(1)
var obj = new String('text')
Boolean类型
建议永远不要用Boolean类型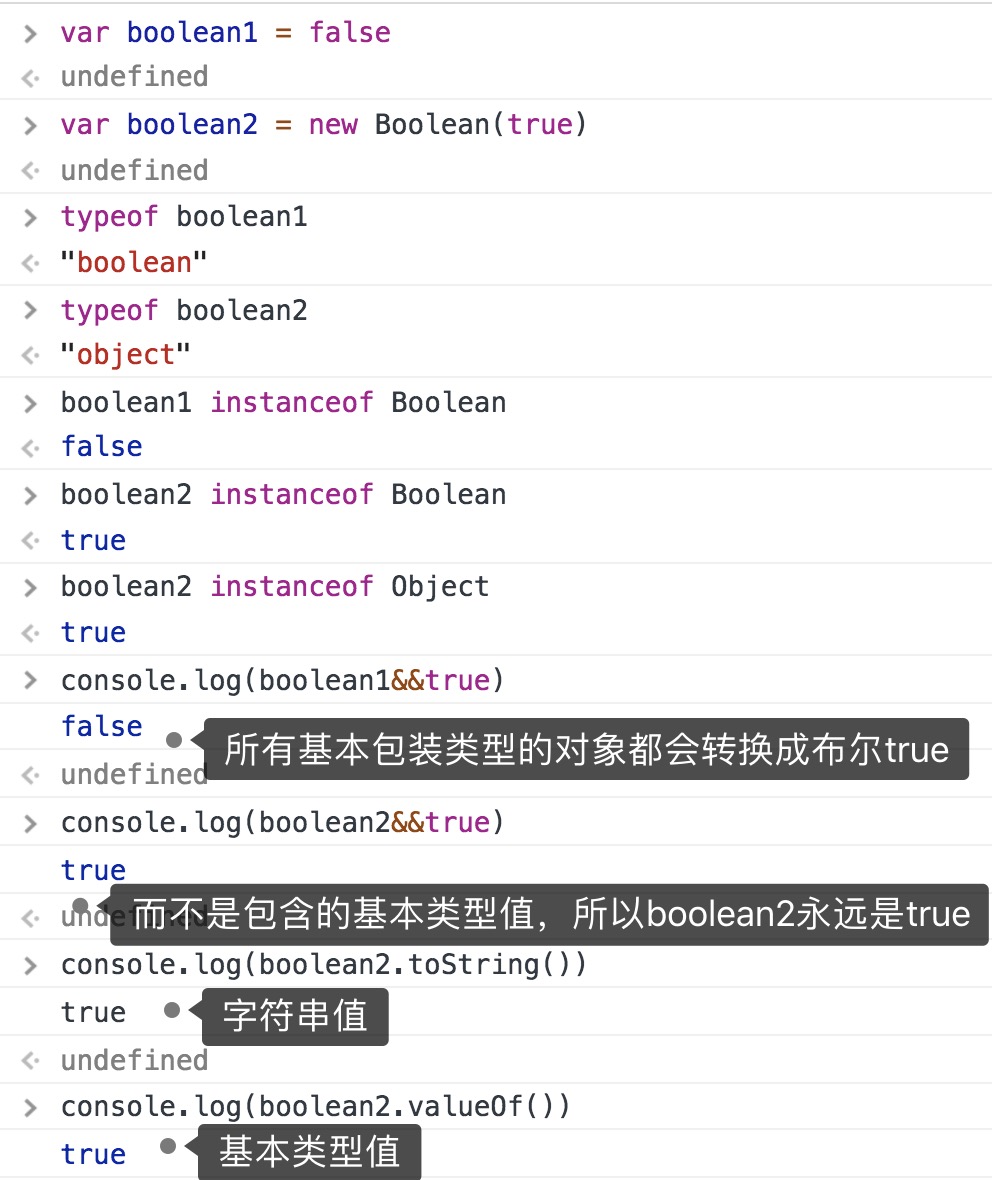
Number类型
⚠️也是由于typeof和instanceof的问题,所以也不建议直接实例化Number类型
继承方法
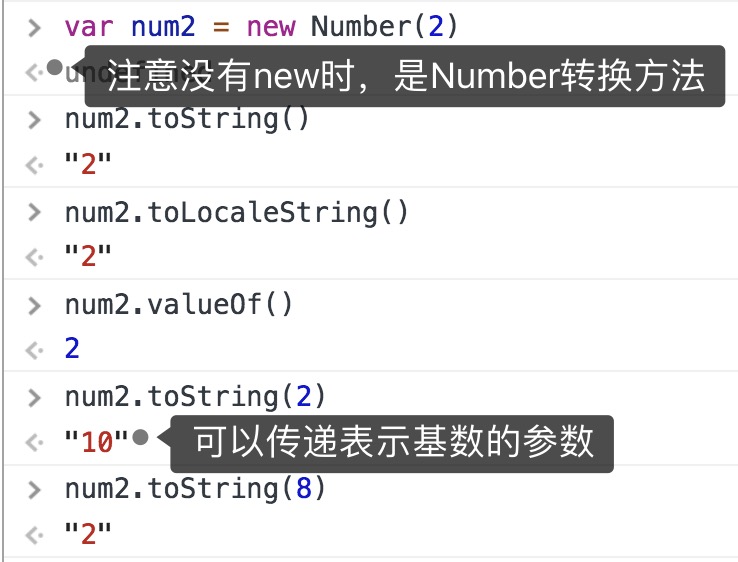
Number类型新增方法
toFixed() 按照指定的小数位返回数值的字符串表示
toExponential() 按照指定的小数位返回数值的指数表示法表示的数值字符串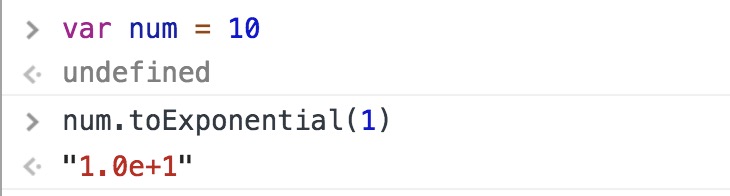
toPrecision() 按照指定的数值所有数字位数(不包含指数部分),更合理的调用toFixed或toExponential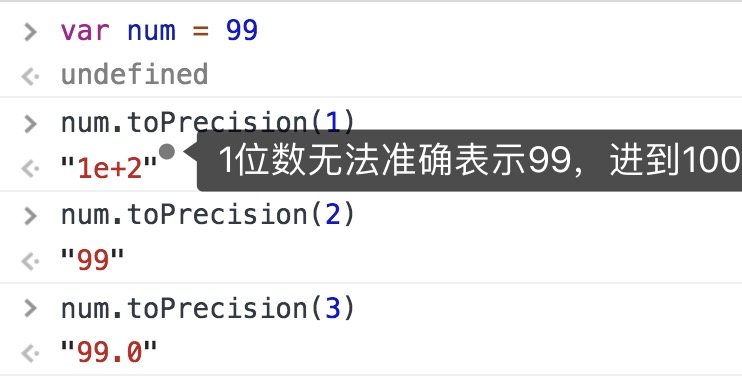
String类型
继承方法
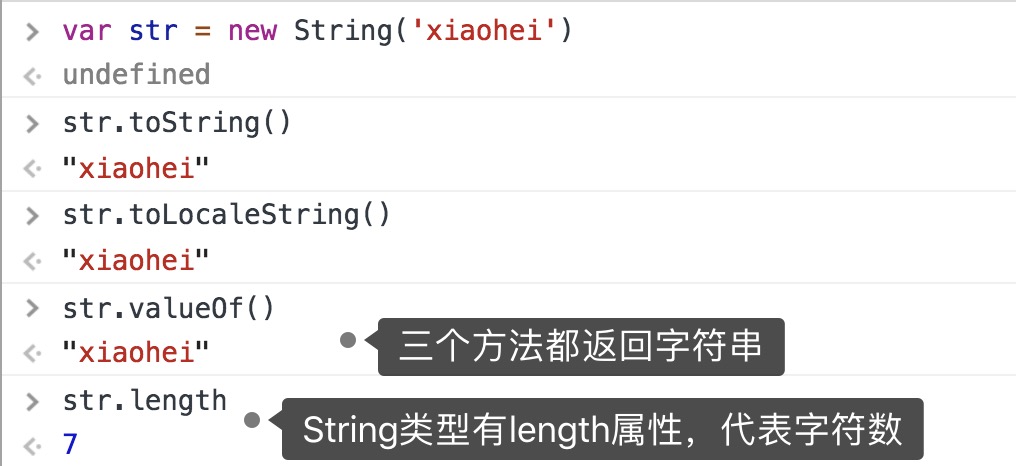
⚠️双字节字符也算是一个字符
字符方法
charAt() 参数是基于0的字符位置,以单字符字符串的形式返回给定位置的字符charCodeAt() 参数是基于0的字符位置,以字符编码的形式返回给定位置的字符
⚠️括号加索引的方法,IE8+支持,IE7会返回undefined(尽管不是特殊的undefined值)
字符串操作方法
concat() 拼接一或多个字符串,返回拼接后的新字符串,原字符串不变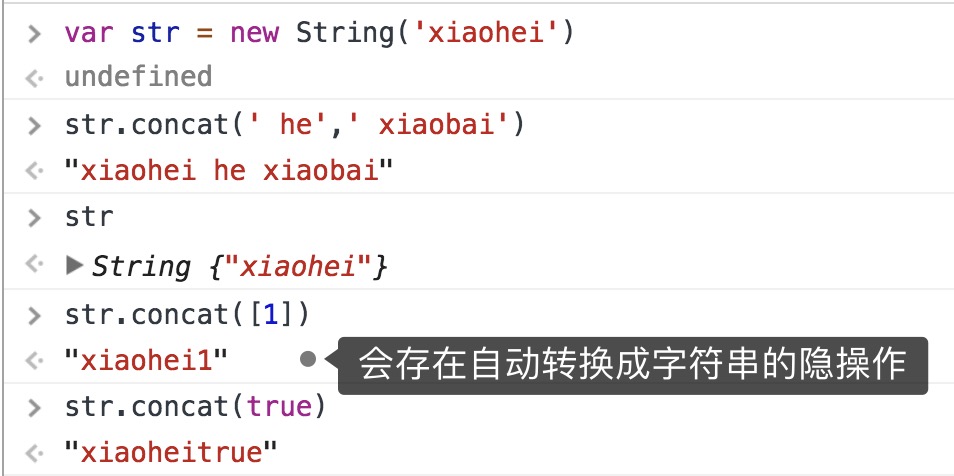
⚠️虽然此方法专门用于拼接字符串,但还是+用的多,更方便易用
slice() 参数一是开始位置,参数二是结束位置的后面位置,返回新的基本类型字符串,原字符串不变,参数是负数的情况将负数加length,参数二大于参数一情况返回空字符串
substring() 参数一是开始位置,参数二是结束位置的后面位置,返回新的基本类型字符串,原字符串不变,参数是负数的情况将负数转换成0,参数二大于参数一情况会自动将较小参数当作开始位置
⚠️substring是小写啊,没有驼峰啊
substr() 参数一是开始位置,参数二是返回字符个数,返回新的基本类型字符串,原字符串不变,参数是负数的情况参数一加length,参数二转换为0
⚠️向substr()传递负数时,IE会返回原字符串,IE9修复了该问题
字符串位置方法
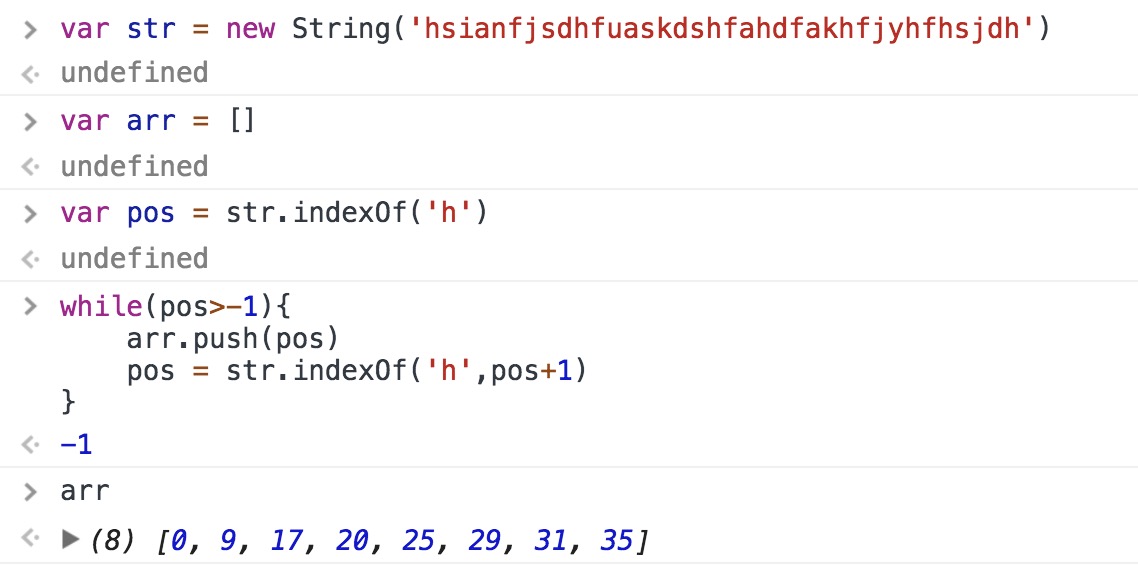
indexOf()/lastIndexOf() 正向/反向搜索子字符串位置,参数一是给定搜索的子字符串,参数二是开始搜索的起始位置(选参),返回给定子字符串的索引,没查到返-1
通过循环查找所有匹配的字符串1
2
3
4
5
6
7var str = new String('hsianfjsdhfuaskdshfahdfakhfjyhfhsjdh')
var arr = []
var pos = str.indexOf('h')
while(pos>-1){
arr.push(pos)
pos = str.indexOf('h',pos+1)
}
trim()方法
trim() 返回删除前置和后缀的所有空格的字符串副本,原字符串不变(IE9+)
此外safari5+,Chrome8+,Firefox3.5+支持非标准的trimLeft() trimRight分别用于删除开头和末尾空格
大小写转换方法
原字符串不变,返回新字符串toLowerCase() toUpperCase() 经典通用方法toLocaleLowerCase() toLocaleUpperCase() 针对特定地区的实现,一些地区和通用方法返回值一样,但是少数语言(如土耳其语)会为unicode大小写转换应用特殊的规则,就必须用针对地区的方法来保证实现正确的转换
⚠️一般不知道代码在哪种语言环境中运行的情况,用针对地区的方法更稳妥
模式匹配方法
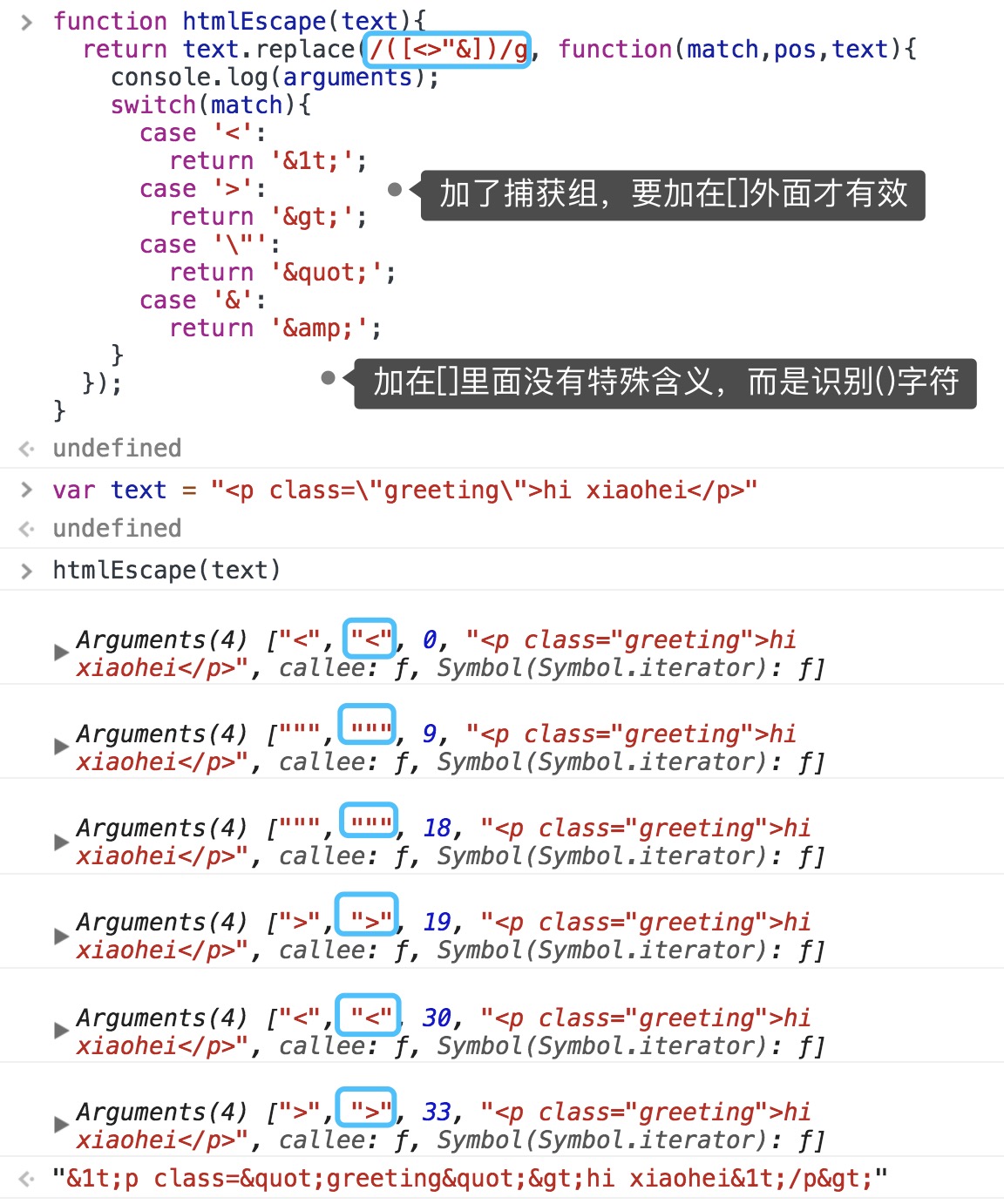
match() 参数是正则表达式或者字符串,本质上与RegExp调用exec()方法一样,返回数组,第一项是匹配项,之后都是捕获组匹配项,同时具备两个额外属性index input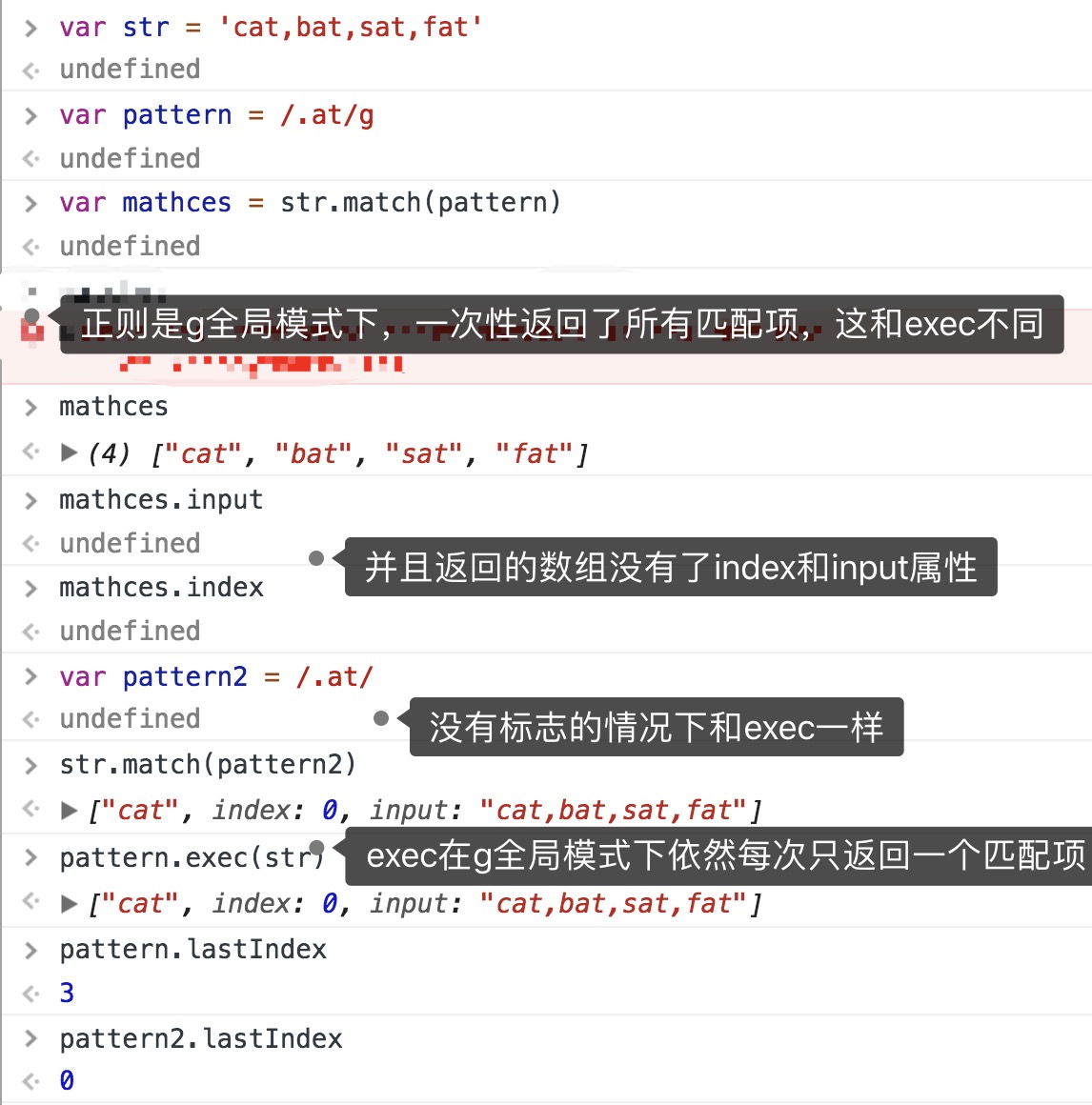

⚠️全局模式下存在差异,如上图
补充存在捕获组的情况,如下图
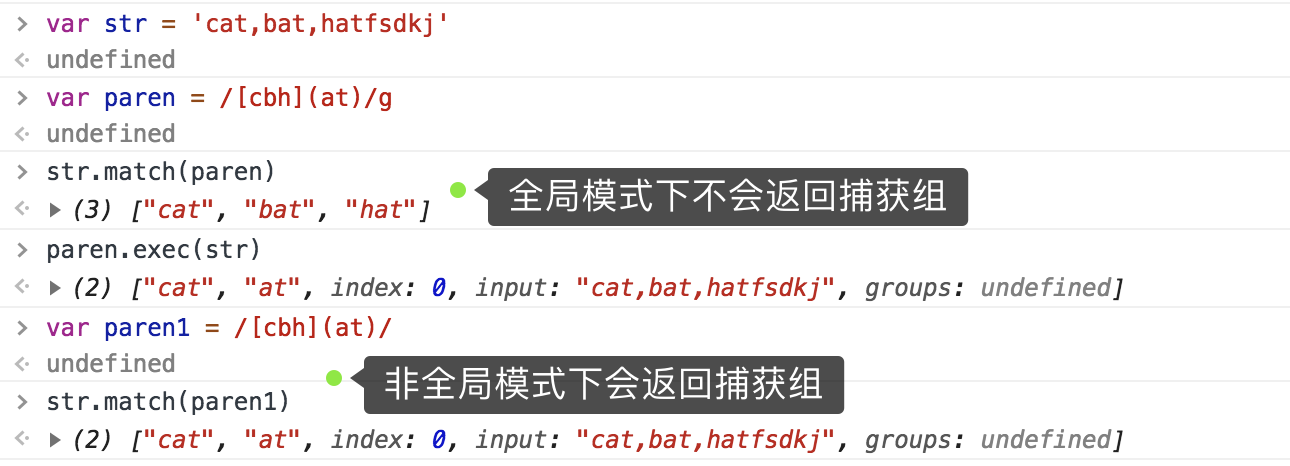
search() 参数是正则表达式或者字符串,始终返回第一个匹配项索引,没有返回-1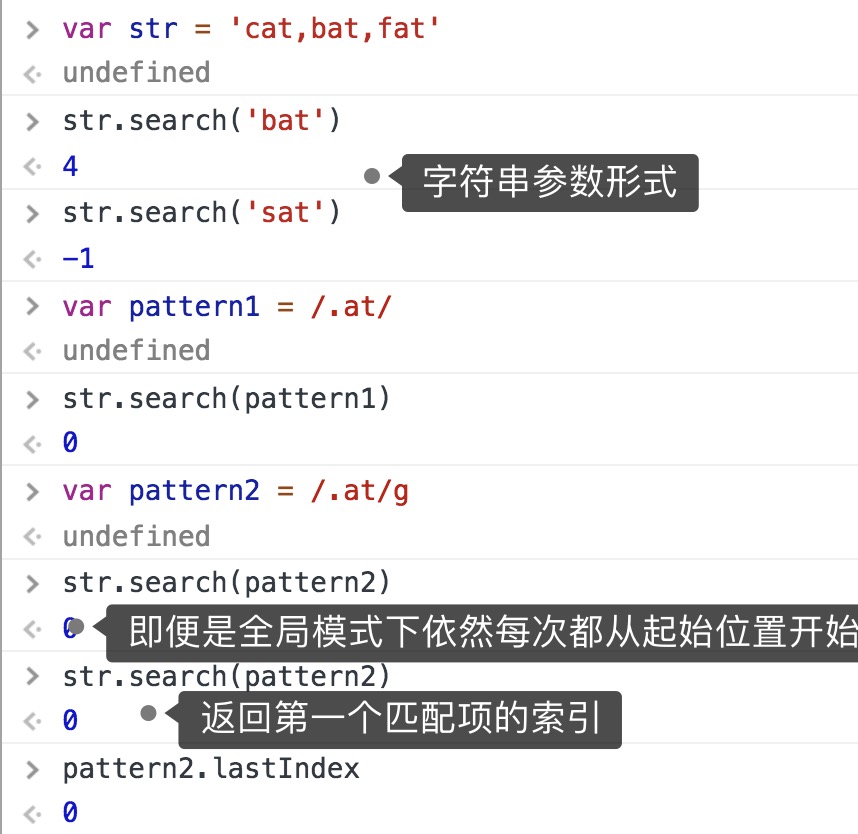
replace() 原字符串不变,返回新字符串
参数一是字符串(只能替换第一个子字符串)/正则(g标志可以替换全部子字符串);
参数二是字符串(可以将正则表达式得到的值插入到结果字符串,由一些特殊字符序列表示)/函数(返回被替换的匹配项,情况1:仅一个匹配项,即无捕获组,函数参数是匹配项、匹配位置、原始字符串;情况2:存在捕获组时,函数参数是匹配项、第一个捕获组、第二个捕获组…、最后两项依然是匹配位置、原始字符串)
| 特殊字符 | 替换文本 |
|---|---|
$$ |
$ |
$& |
最近一次匹配项RegExp.lastMatch |
$` |
RegExp.leftContext |
$' |
RegExp.rightContext |
$n |
n是1-9,n个捕获组匹配项 |
$nn |
nn是01-99,nn个捕获组匹配项 |

1 | function htmlEscape(text){ |
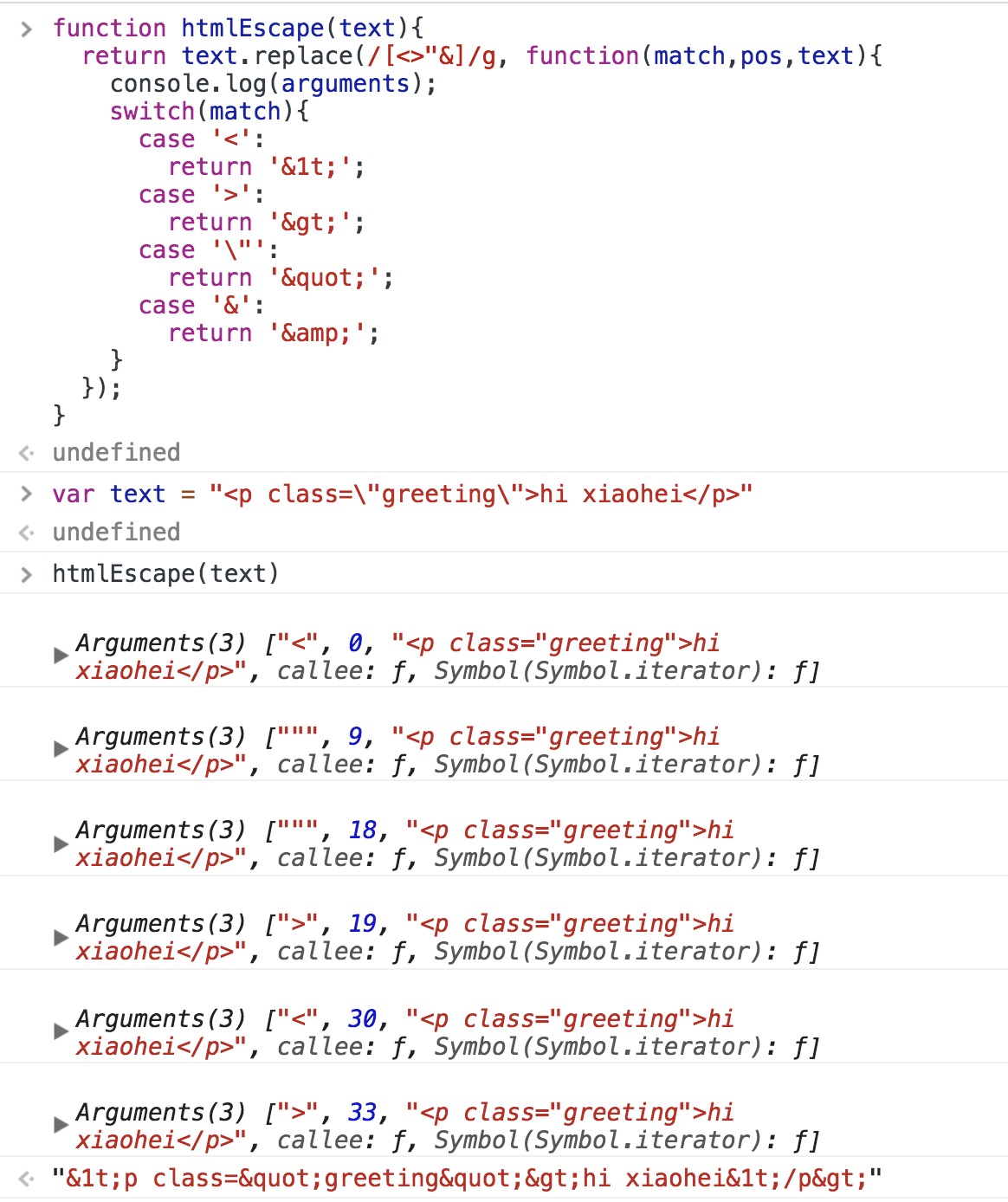
split() 以指定分隔符分割成多个子字符串作为数组项返回数组,参数一分隔符是字符串/正则,参数二(可选)指定数组大小

⚠️那个正则\没懂啊,尝试也并不能匹配到\。。。
规定应把捕获组拼接到结果数组中(IE9+),捕获组没匹配到返回undefined,下图延续上图上下文
⚠️但是浏览器实现各异,需要用前测试好各浏览器
localeCompare()方法
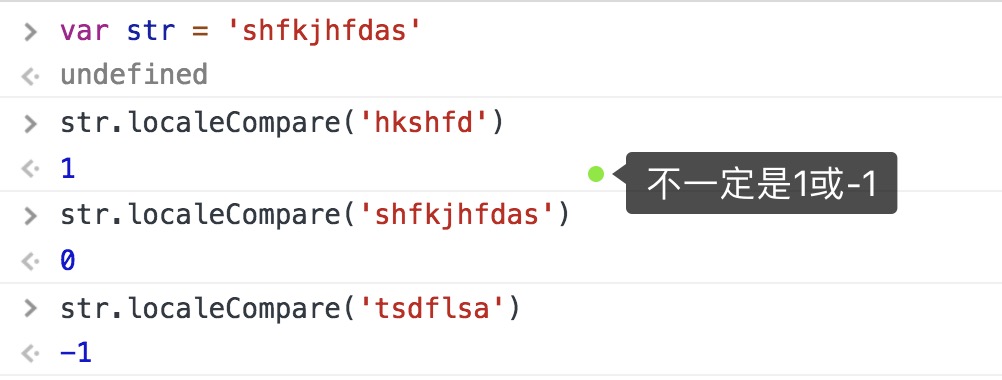
localeCompare() 与传参字符串比较字符编码位置,返回逻辑和数组的sort传参函数一样,排在参数后面说明大返回正数(未必是1),等于返回0,否则返回负数(未必是-1)
⚠️由于此方法返回值不一定是1/-1,所以用大于0小于0比较稳妥
⚠️此方法实现所支持的地区决定方法行为,即美国区分大小写,大写字母字符编码小于小写字母,而其他地区不一定是这种情况
fromCharCode()方法
fromCharCode() String构造函数的静态方法,接收多个字符编码参数,返回字符串,本质与实例的charCodeAt()相反功能
HTML方法
专门用于简化常见HTML格式任务的方法
不推荐用,因为无法表达语义